

Em negócios que tomam decisões informadas, existem muitas formas de extrair insights a partir de dados, uma delas é usando Python para análise de dados.
A análise de dados com Python tem se tornado muito popular entre cientistas e analistas de dados, por oferecer recursos, bibliotecas vastas e boas funcionalidades aos profissionais de dados que usam essa linguagem de programação.
Neste artigo, entenda o que é a análise de dados com Python, porque usar essa linguagem de programação para análise de dados, as principais bibliotecas de Python e mais!
O que é a análise de dados com Python?
Python é uma linguagem de programação que tem se tornado muito popular na comunidade de analistas e cientistas de dados.
Tomar decisões baseando-se em dados reais do negócio tem pautado a prática de diversas empresas que buscam ser mais assertivas e estratégicas.
Para isso, a coleta, tratamento, análise e visualização de dados deve ser feita de forma otimizada e focada em extrair ao máximo insights valiosos para o negócio, ao mesmo tempo que é eficiente.
Assim, a linguagem de programação Python tem sido a escolha principal de profissionais de data science. Essa linguagem conta com um vasto ecossistema de bibliotecas, que são ideais para oferecer suporte à manipulação e análise de dados.
Além disso, fornece outros recursos que amparam esse processo, como a visualização de dados a partir de gráficos de fácil entendimento, ou suporte ao machine learning e deep learning a partir de bibliotecas direcionadas para este fim.
Assim, Python é uma linguagem de programação muito adequada para realizar processos de análise de dados de forma simples e intuitiva, ao mesmo tempo que conta com bibliotecas completas que otimizam esse processo.
Por que utilizar Python para análise de dados?
Há muitas vantagens em utilizar Python para análise de dados. Confira algumas delas a seguir!
Diversidade de bibliotecas disponíveis
Uma das principais vantagens de usar Python para analisar e visualizar dados é a disponibilidade de bibliotecas dedicadas para esse fim nessa linguagem de programação.
As bibliotecas oferecem ferramentas para manipular, organizar e transformar dados, criar gráficos visuais, entre outros recursos essenciais para uma análise de dados assertiva.
Algumas bibliotecas usadas na análise de dados com Python, são:
- Pandas;
- NumPy;
- Seaborn;
- Matplotlib,
- TensorFlow;
- PyTorch, etc.
Comunidade consolidada de profissionais
Outro grande benefício é a ampla e consolidada comunidade de profissionais que usam Python para análise de dados.
Como mencionado, Python tem se tornado muito popular entre analistas de dados e áreas correlatas. Isso faz com que a comunidade de profissionais que usam essa linguagem de programação seja muito forte.
Assim, profissionais de dados, iniciantes ou não, podem contar com o suporte da comunidade, além de poder ter trocas significativas para aprimorar tanto seu trabalho, quanto para contribuir com a comunidade.
Outra vantagem é que além de suporte, os profissionais também recebem atualizações frequentes das bibliotecas de Python, otimizando a atuação com esse tipo de linguagem de programação.
Pode ser usada para outras finalidades
Além de poder ser usada para análise de dados, a linguagem de programação Python também serve para outras finalidades no que se refere à programação. Assim, é uma linguagem versátil e multifuncional, e pode ser amplamente usada para executar vários tipos de projetos.
Por exemplo, é possível usar Python para desenvolvimento web, com bibliotecas como Flask e Django, assim como, para a automação de tarefas e processos, desenvolvimento de softwares e jogos, entre outros.
Fácil de aprender
Muitas pessoas consideram que Python é uma linguagem de programação mais fácil de aprender e executar. Isso ocorre por diversas razões, como:
- Possui uma sintaxe clara e fácil de compreender, sendo mais legível e direta, diferente de outras linguagens de programação como C++;
- Usa “indentação”, uma hierarquização de elementos que tornam a linguagem mais organizada e limpa e portanto, mais fácil de aprender e executar. Enquanto em outras linguagens o uso de símbolos como chaves e parênteses é comum para delimitar o código, em Python, a indentação deixa esse processo mais organizado desde o início;
- É open source, o que significa que opera em código aberto e oferece muitos materiais, documentações, recursos e bibliotecas para quem está começando;
- Possui uma comunidade engajada e disposta a ajudar profissionais iniciantes, tornando o processo mais imersivo e otimizado.
Principais bibliotecas para análise de dados com Python
Um dos fatores que fazem a linguagem de programação Python excelente para a análise de dados são suas bibliotecas bem estruturadas, vastas, constantemente atualizadas e de alto nível.
As principais bibliotecas para fazer análise de dados com Python, são:
Pandas
Uma das bibliotecas mais conhecidas e mais usadas por profissionais de dados, ela permite que o usuário manipule, transforme e analise dados de maneira muito otimizada.
A Pandas possibilita a leitura em vários formatos, como SQL, CSV, Excel, etc., além de funcionar, principalmente, com dois tipos de estrutura de dados: Series e DataFrames.
DataFrames seguem uma estrutura semelhante a uma planilha de Excel, já Series, se refere a um array unidimensional, que pode ser entendido como uma lista simples de valores. Outros elementos da Pandas são o manejo com dados nulos e operações de merge e join.
NumPy
A biblioteca NumPy compila funções relacionadas à álgebra linear e computação numérica, trabalhando com arrays multidimensionais, cálculos rápidos, entre outras funcionalidades.
Além disso, a biblioteca NumPy está no núcleo de basicamente todos os programas e bibliotecas que lidam com operações matemáticas e usam a linguagem de programação Python.
Como por exemplo, a própria biblioteca Pandas baseia sua estrutura de dados (DataFrames e Series) em arrays de NumPy.
Matplotlib
A Matplotlib é uma biblioteca orientada para a visualização de dados, possibilitando a criação de gráficos 2D, 3D, de linhas, de barras, dispersão, histogramas, etc.
Nela, pode-se personalizar a visualização de dados de acordo com as necessidades do profissional, garantindo muita flexibilidade para a criação de gráficos para análise de dados.
Seaborn
A biblioteca Seaborn funciona em cima da biblioteca Matplotlib, ou seja, também serve para a visualização de dados. A diferença está na possibilidade de criar gráficos mais agradáveis visualmente, tornando a análise de dados mais intuitiva.
Funções essenciais para fazer análise de dados com Python
Há algumas funções e comandos em Python que são usados para executar a análise de dados com essa linguagem de programação.
Essas funções têm relação com as bibliotecas usadas nesse processo e servem para importar, ler, manipular, transformar e visualizar os dados. A biblioteca mais usada, Pandas, realiza grande parte do processo de análise de dados e possui funções cruciais para esse processo.
O primeiro passo para começar uma análise de dados, é importar uma biblioteca de Python para o código atual do projeto para adicionar as funcionalidades e outros elementos ao código.
Para isso, usa-se o comando: import. Por exemplo, se você for trabalhar com a biblioteca Pandas, utiliza-se a função import pandas as pd para carregar essa biblioteca no código sendo usado.
Em seguida, os principais comandos para fazer análise de dados com Python usando Pandas, são:
read_*()
Para começar um projeto de análise de dados é necessário carregar os dados no DataFrame. Assim, a função read_*(), importará dados de um arquivo no formato escolhido para que sejam analisados no projeto.
Alguns formatos mais usados são:
- read_csv
- read_excel;
- read_sql;
- read_html;
- read_json, etc.
head()
O comando head() apresenta as primeiras linhas do banco de dados carregados para te ajudar a visualizar melhor os dados presentes neste dataset.
Normalmente, se o analista de dados não inserir nenhum valor, essa função exibe as cinco primeiras linhas do banco de dados.
describe()
A partir do momento que você importou dados para analisar e obteve uma visão geral dessas informações, usar a função describe(), vai fornecer algumas descrições das variáveis numéricas importantes dos dados carregados, como uma média de valores, um desvio padrão, entre outras.
DataFrame.dtypes
DataFrame.dtypes é um atributo usado para identificar os tipos de dados em cada coluna do dataset, interpretando como Python lê esses dados em sua biblioteca.
Utiliza-se esse atributo com frequência no processamento de dados, para limpar ou transformar dados antes de prosseguir com a análise.
drop()
A função drop() auxilia na remoção de linhas ou colunas irrelevantes da tabela de dados. Esse comando ajuda a filtrar aquilo que é importante para uma análise de dados mais aprofundada.
fillna()
Utiliza-se a função fillna() para preencher valores ausentes em um dataset de Python.
Esse processo é fundamental no tratamento de dados, uma vez que se aparecerem em uma análise como valores nulos por erro de entrada ou qualquer outra razão, podem atrapalhar a análise correta dos dados.
groupby()
No processo de análise de dados, você poderá estabelecer critérios e em alguns momentos, precisará fazer o agrupamento de tabelas e dados para realizar uma análise.
A função groupby() serve para agrupar os elementos de um dataset, que normalmente são usados para agregar valores do conjunto de dados.
Como fazer análise de dados com Python
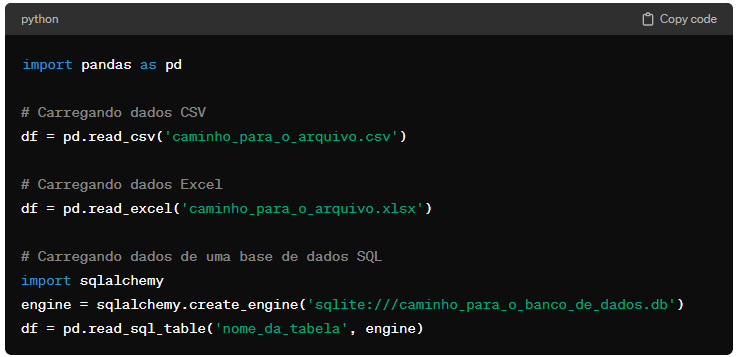
1. Importação de Dados
O primeiro passo na análise de dados é importar os dados para o ambiente de análise. Python suporta a leitura de uma vasta gama de formatos de dados, incluindo CSV, Excel, JSON, e bases de dados SQL. Bibliotecas como Pandas facilitam a importação e manipulação de dados tabulares.
2. Limpeza e Preparação dos Dados
Após a importação, é comum os dados conterem problemas como valores ausentes, duplicatas ou erros de formato. A biblioteca Pandas oferece várias funções para lidar com esses problemas, permitindo limpar e preparar os dados para análise.
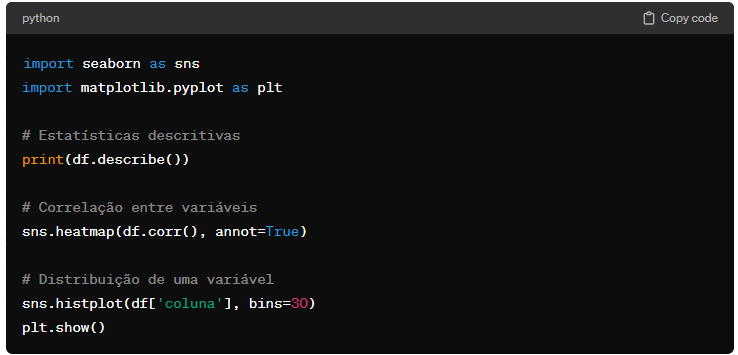
3. Análise Exploratória de Dados (EDA)
A Análise Exploratória de Dados é um passo crucial para entender a natureza e as características dos dados. Isso pode incluir a geração de estatísticas descritivas, a identificação de correlações entre variáveis e a exploração de distribuições de dados. A biblioteca Pandas junto com Seaborn e Matplotlib são excelentes para essas tarefas.
4. Modelagem de Dados
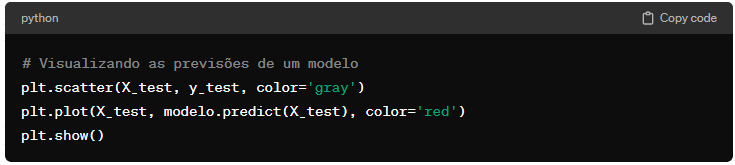
Com os insights obtidos na EDA, pode-se aplicar modelos estatísticos ou de machine learning para fazer previsões ou agrupamentos. Scikit-learn é uma biblioteca poderosa para modelagem de dados, oferecendo uma ampla gama de algoritmos para classificação, regressão, clustering, entre outros.
5. Visualização de Resultados
A visualização dos resultados é fundamental para interpretar os modelos de dados e comunicar as descobertas. Bibliotecas como Matplotlib e Seaborn permitem criar uma ampla gama de visualizações, desde gráficos de linhas e barras até mapas de calor e scatter plots.
Conclusão
Vimos aqui que utilizar Python para análise de dados é uma prática cada vez mais frequente entre cientistas e analistas de dados por oferecer diversas vantagens.
A linguagem conta com funcionalidades, bibliotecas e recursos vastos para auxiliar o processo de análise, transformação e visualização de dados, além de ser fácil de aprender e executar, sendo uma ótima aliada de profissionais da área.
Para negócios digitais que estão constantemente desenvolvendo novos produtos, a demanda pelo conhecimento em Python está cada vez maior. Sendo assim, seja você um profissional de dados ou empreendedor, vale a pena estar atento a esse movimento.
Caso queira entender o assunto com mais detalhes, recomendamos o livro “Python Para Análise de Dados” de Wes McKiney.
Leia também:



